For those interested in watching our paper presentations at the Greek and Latin in an Age of Open Data conference, see the live stream and links to youtube videos here. We have one more talk scheduled for 11 am Eastern Time, "Digital Access and the Practicality of Citizen Scholarship." You can also see our first talk, "A Redefinition of Classical Scholarship", on Day 2 of the conference.
Wednesday, December 3, 2014
Wednesday, November 19, 2014
Greek and Latin in an Age of Open Data
We're pleased to announce that the Homer Multitext project will be presenting two papers at the "Greek and Latin in an Age of Open Data" conference hosted by the Open Philology Project at the University of Leipzig, December 1-4. You can read our papers "A Redefinition of Classical Scholarship" and "Open Access and the Practicality of Citizen Scholarship" from the conference program.
Monday, November 3, 2014
Upcoming Workshop and Roundtable
We are proud to announce that four HMT collaborators, Neel Smith, Nikolas Churik, Brian Clark, and Stephanie Lindeborg, will be featured at the 'Scholarship in Software, Software as Scholarship: From Genesis to Peer Review' workshop and roundtable in Bern on January 29th, 2015. Their proposal, titled "Composing living scholarship: applying automated acceptance tests to scholarly writing', will discuss the implementation of dynamic content in scholarly prose, resulting in documents that are live instead of fixed texts. Stay tuned for more news on this exciting topic!
Friday, October 24, 2014
Open Access Week at the Homer Multitext project
This week is Open Access Week, an annual event promoting open access as a norm in scholarly work. At Holy Cross, three members of the Homer Multitext project, Nik Churik '15, Brian Clark '15, and Melody Wauke '17, took part in a panel along with presenters from the faculty and the library staff. (Below, Brian and Melody with Nik's wristwatch in the background as the panellists are introduced in the very traditional setting of a library reading room.)

In contrast to the other speakers, the HMT members traced a connection from open access to the potential to replicate and verify scholarly work, and concluded that open access is not simply one convenient option among others, but an ethical obligation. The audience seemed to me to struggle with this idea, despite the fact that it was a small, self-selected group already interested in the subject.
One institution that deserves recognition for taking open access very seriously is the Bayerische Staatsbibliothek, where hundreds of manuscripts are being digitized, and made available on line under the terms of a Creative Commons license. (Some of the older digitization includes black and white images only, but more recent additions offer very high quality color images.) Four of the Greek manuscripts they have already digitized include Homeric material, and thanks to the library's use of a standard open license, we will be including them in future releases of the Homer Mutlitext's archive. The processor-intensive conversion of the images to the zoomable format we use in our citable image service is underway, and you can now look at the first of the Munich manuscripts on our test site. If the manuscript photography we have already published has awakened your interest in the various prose paraphrases and metrical summaries of the Iliad they include, you will no doubt enjoy the Bayerische Staatsbibliothek's Codex Graecus 88 as well.
In contrast to the other speakers, the HMT members traced a connection from open access to the potential to replicate and verify scholarly work, and concluded that open access is not simply one convenient option among others, but an ethical obligation. The audience seemed to me to struggle with this idea, despite the fact that it was a small, self-selected group already interested in the subject.
One institution that deserves recognition for taking open access very seriously is the Bayerische Staatsbibliothek, where hundreds of manuscripts are being digitized, and made available on line under the terms of a Creative Commons license. (Some of the older digitization includes black and white images only, but more recent additions offer very high quality color images.) Four of the Greek manuscripts they have already digitized include Homeric material, and thanks to the library's use of a standard open license, we will be including them in future releases of the Homer Mutlitext's archive. The processor-intensive conversion of the images to the zoomable format we use in our citable image service is underway, and you can now look at the first of the Munich manuscripts on our test site. If the manuscript photography we have already published has awakened your interest in the various prose paraphrases and metrical summaries of the Iliad they include, you will no doubt enjoy the Bayerische Staatsbibliothek's Codex Graecus 88 as well.
Thursday, October 2, 2014
A Recent Mention of the Homer Multitext Project
Check out this recent paper by Greg Crane on computational humanities, the HMT, and citizen science!
Sunday, September 7, 2014
Summer Researchers Present Their Work At Holy Cross
Back to school season is here and while most students are concerned with the first week of classes, several Homer Multitext researchers joined their peers at Holy Cross's Annual Summer Research Symposium this Friday, September 5th. Our researchers stood alongside projects from the sciences and humanities, all of which were conducted at the College of the Holy Cross this summer. Hogan Ballroom was packed from 1-4pm.
 |
| Brian Clark '15, Andrew Boudon '15, and Nik Churik '15 (not pictured Alex Simrell '16 and Chris Ryan '16) |
After a solid summer of creating editions of Iliad 11 in two manuscripts, they had a lot of say on scribal methods and repetition of content in the scholia. We look forward to hearing more details about their discoveries as the Fall progresses!
 |
| Brian Clark '15 shares his research with Holy Cross Classics professor |
Saturday, August 30, 2014
New content, new contributors
Eric Raymond popularized the phrase "release early, release often" as a philosophy for software development. It works for digital scholarship, too.
We're happy to announce today an early release of a facsimile browser incorporating new material from our photography in the Escorial last summer. The digital facsimile edition requires data about the manuscripts (including what folios appear in what sequence), an index aligning each folio with a canonical citation of lines of the Iliad, and an index identifying which side of which folio each image illustrates. A group of dedicated and talented volunteers (some shown in the photo) has been meeting regularly on Friday afternoons to put this material together for the Escorial Υ.1.1 manuscript, prior to beginning work on a full diplomatic edition of the text (as others are already doing for the Venetus A and Venetus B codices).
Perhaps even more remarkable than the volunteers' rapid mastery of Escorial Υ.1.1's Byzantine script is the fact that all of the students are in their first year of Greek. If you're not accustomed to learning about the transmission of Homer from first-year Greek students, a Friday afternoon with this group is enlightening.

You will undoubtedly see postings on this blog in the future announcing further releases of material from "Team Escorial Υ.1.1." In addition to the puzzles they've had to solve to make today's release available, they are compiling careful observations that will lead to a helpful guide to the paleography of Escorial Υ.1.1, and have already noted a number of unpublished or unappreciated discrepancies bewteen Escorial Υ.1.1 and other manuscripts that are forcing all of us working on the Homer Multitext project to reassess entirely the traditional scholarly views on the (b) family of manuscripts of the Iliad.
The Escorial Υ.1.1 group has currently indexed more than half of the manuscript: we're including folios 1 recto - 109 recto (covering Iliad books 1-8) in today's release.
Our profound thanks to all members of the group (alphabetically):
- Matthew Angiolillo
- Neil Curran
- Maria Jaroszewicz
- Alex Krasowski
- Becky Musgrave
- Kathleen O'Connor
- Anne Salloom
- Megan Whitacre
Monday, August 11, 2014
New publication of Homer Multitext research
If you would like to know what kind of research is being enabled by the Homer Multitext project, check out the recent publication in the Sunoikisis Undergraduate Research Journal of work by Matthew Angiollilo, Thomas Arralde, Melissa Browne, Nik Churik, Brian Clark, Stephanie Lindeborg, Rebecca Musgrave, and Neel Smith, in which the construction, organization, and layout of three Byzantine manuscripts of the Iliad are discussed.
Friday, August 1, 2014
First publication of software for HMT services
In February, we announced the first publication of the HMT project’s archival data. Today, we are releasing the first published version of hmt-digital, a java servlet providing digital services for working with the project archive.
Version 1.0 is now installed at http://www.homermultitext.org/hmt-digital, where you can routinely expect to find the currently published services using the currently published version of the data archive. We continue to run a test site at http://beta.hpcc.uh.edu/tomcat/hmt-digital/. The test set normally runs in-progress versions of hmt-digital, and uses unpublished versions of our data archive.
Our software, like all the data in our archive, is openly licensed. If you’d prefer to run a local installation of the hmt-digital services, you’ll find instructions on the README for the project’s github repository.
Links
- HMT project installation of hmt-digital 1.0: http://www.homermultitext.org/hmt-digital
- github repository: https://github.com/homermultitext/hmt-digital
Saturday, July 26, 2014
The traditional Trojan assembly
Over on our companion Oral Poetry blog, I continue my series on the Trojan catalogue in conjunction with and parallel to Casey’s blogging of the Catalogue of Ships. In my first post I looked at how the Trojans are introduced in our Iliad and how to understand some of the traditional language used. In my second post I continue looking at Iris's message to the Trojan assembly and how its use of traditional language both sets the “now” of the story into action and simultaneously evokes earlier episodes of the war.
 |
| Iris |
Friday, July 25, 2014
It's National Sysadmin Day
Followers of the Homer Multitext blog may not immediately identify the last Friday in July as National Sysadmin Day, but we're acutely aware of our debt to the administrators who keep all the systems we depend on running smoothly. I would especially like to acknowledge the support we have received from Alan Pfeiffer-Traum at the University of Houston. Without Alan's work, I doubt we could be serving the thousands of on-line images of manuscripts you can browse today from the HMT project.
Thanks to the sysadmins at every site where Homer Multitext teams are working!
Thanks to the sysadmins at every site where Homer Multitext teams are working!
Monday, June 30, 2014
Seminar 2014 Presentations
We have reached the time for CHS Summer Seminar 2014 presentations! We are looking forward to our participants presenting on a variety of topics seen in the scholia of Iliad 12. We will be live streaming the presentations. If you would like to watch the presentations live see the following instructions and caveats:
The best place to see the stream is on the CHS network.
If you are not able to come to the CHS, you can try the following link: rtsp://stream.chs.harvard.edu/HouseA.
Note that Mac users will have to use QuickTime 7 Player (a very old version) because Apple has deleted RTSP format from QuickTime 10: http://support.apple.com/kb/dl923.
The best place to see the stream is on the CHS network.
If you are not able to come to the CHS, you can try the following link: rtsp://stream.chs.harvard.edu/HouseA.
Note that Mac users will have to use QuickTime 7 Player (a very old version) because Apple has deleted RTSP format from QuickTime 10: http://support.apple.com/kb/dl923.
The VLC player works too, sometimes: http://www.videolan.org/.
If you have any trouble accessing the stream, but would like to watch the presentations, they will be recorded and posted at a later date.
Stay tuned for more blog posts based on the Summer 2014 presentations and on other work by our participants.
Sunday, June 29, 2014
Iliad 12 as Oral Traditional Poetry
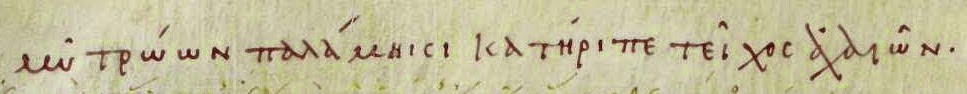
Each year at the Homer Multitext Summer Seminar we introduce a new group of students to the scholarly principles that underlie the Homer Multitext project, which are grounded in the research and fieldwork of Milman Parry and Albert Lord on oral poetry. In addition to talking in a broad way about how the Iliad was composed and transmitted over time, we also think out loud about how our understanding of Homeric poetry as an oral traditional system affects how we interpret the poetry. And each year we ground that discussion by focusing on a particular book of the Iliad. The students create an XML edition of the text and scholia for that book in the Venetus A manuscript, and in a series of sessions we talk as a group about the poetics of that book. This year's book is Iliad 12 and it has led us to discuss such topics as the building of and battle before the Achaean wall (which caused such consternation among Analyst scholars in the 19th and early 20th centuries), the poetics of battle and the way that they overlap with the poetics of Catalogue poetry such as we find in Iliad 2, and the way that repetition functions in oral poetry, as well as text critical questions such as how to treat verses that are omitted from one or more of our medieval manuscripts (such as 12.219). These discussions have fostered a great deal of creative exchange among the participating students and faculty (who this year include Michiel Cock, Casey Dué, Eric Dugdale, Mary Ebbott, Olga Levaniouk, Gregory Nagy, Corinne Pache, Ineke Sluiter, and Neel Smith). This exchange has in turn influenced the latest post on our Oral Poetry blog, "Walk On Characters in the Iliad."
Thursday, June 26, 2014
How to Build a Community of Scholars Through Pancakes
One of the most integral components of the HMT is team collaboration, not just students working with each other in individual groups, but students sharing information across teams and working closely with faculty. Sometimes this collaboration takes place within one institution, but as HMT spreads through the summer seminar our collaborative teams find themselves miles and even oceans away. With one week left in the seminar, we are beginning to reflect on ways for the participants to bring their research home with them and continue this great scholarly work. Herein lie the pancake dinners. Collaborative research is a social endeavor and I would suggest that someone you are willing to share a pancake with makes an excellent research partner.
This past Wednesday evening, in the spirit of sharing culture and good food, some participants of the CHS Summer 2014 Seminar hosted a Dutch Pancake Potluck Dinner. Two of our students from Leiden University made authentic Dutch pancakes and the evening was generally agreed to be a massive success. Throughout the evening I snapped pictures, intending to post something nice about what our participants do when they aren’t furiously reading scholia. As I pondered what I was going to write, I reflected on the reasons why the dinner was such a success and why it was in many ways just as important as any seminar session on the oral poetics of Homer or how to code TEI markup in our xml editions.
Sharing food and recipes in this social environment is a great model for how to continue research after the summer seminar. The exchange of information doesn’t have to end and hopefully some really excellent pancakes will help solidify the relationships of the summer seminar to facilitate not just more great food but more great research.
 |
| What does one eat with Dutch pancakes? |
 |
| Syrup is key! |
Sharing food and recipes in this social environment is a great model for how to continue research after the summer seminar. The exchange of information doesn’t have to end and hopefully some really excellent pancakes will help solidify the relationships of the summer seminar to facilitate not just more great food but more great research.
 |
| Our community of scholars |
Tuesday, June 24, 2014
CHS Seminar 2014
For the fourth summer in a row, the Homer Multitext project is running a two week seminar on digitally editing the Venetus A manuscript. Twenty-two undergraduates, graduates, and professors have been hard at work, creating a digital edition of Iliad 12 in the Venetus A. Many have likened work on this project to building a ship while sailing it and these researchers have shown great flexibility learning both the 10th century Byzantine hand and at the same time learning how to conduct their editing using virtual machines, a new technology added to the project this summer.
 |
| Front row (left to right): Olga Levaniouk, Mary Ebbott, Melody Wauke, Malia Piper, Sam Hill, Stephanie Lindeborg Middle row (left to right): Corinne Pache, Ineke Sluiter, Shannon Young, Suzanne Verkade, Solomon Umana, Amie Goblirsch Back row (left to right): Ian James, Casey Dué, Neel Smith, Kirsten Haijes, Charlie Schufreider, Eric Dugdale, Michiel Cock, Jacob Luber, James Skoog, Ian Tewksbury |
We look forward to great things from this team of researchers as they tackle questions that have puzzled scholars on Iliad 12 and have plagued readers of the scholia, and look to update Allen’s landmark article, "On the Composition of Some Greek Manuscripts," with live references to the digital material now available through HMT.
 |
| Left to right: Suzanne Verkade, Corinne Pache, Malia Piper, Shannon Young, Sam Hill, Jacob Luber, and Michiel Cock |
 |
| Left to right: Shannon Young, Melody Wauke, and Michiel Cock |
Monday, June 23, 2014
The scribal process of handling “forgotten” lines in two manuscripts of the Iliad: Escorial Upsilon 1.1 and Venetus A
A guest post by Holy Cross undergraduate research teams: Debbie Sokolowski ’14 and Drew Virtue ’17; Becky Musgrave ’14 and Chris Ryan ’16
ἐν δ’ ἐτίθει δύο κῆρε τανηλεγέος θανάτοιο.
On 286 verso, we encountered an instance in which the scribe seems to have accidentally omitted a line of the text and later inserted it. At the top of the folio, above two scholia, is the omitted line (212): ἕλκε δὲ μέσσα λαβών. ῥέπε δ᾽ Ἕκτορος αἴσιμον ἦμαρ·


Often when the Homer Multitext team edits manuscripts throughout the year we encounter irregularities in the way the folios are laid out. One case of this is the way scribes deal with lines of the Iliad that they either forgot or decided not to include within the main text. Debbie Sokolowski and Drew Virtue discovered one example of this in their editing of book 22 in Venetus A this year, on folio 286 verso. The lines are Iliad 22.210–22.213:
ἐν δ’ ἐτίθει δύο κῆρε τανηλεγέος θανάτοιο.
τὴν μὲν Ἀχιλλῆος. τὴν δ᾽ Ἕκτορος ἱπποδάμοιο·
ἕλκε δὲ μέσσα λαβών. ῥέπε δ᾽ Ἕκτορος αἴσιμον ἦμαρ·
ᾤχετο δ᾽ εἰς Ἀΐδαο· λίπεν δέ ἑ Φοῖβος Ἀπόλλων·
This omitted line is identified with a β in the margin. In the main text lines 211 and 213 are marked with an α and γ, respectively, signaling to the reader that the lines should read in the order of α, β, γ. This omission can reveal many important insights about the scribe’s process in composing the Venetus A. We know that the scribe normally writes 25 lines of the poem on each folio. Including the omitted line, folio 286 verso still follows this rule. Therefore, we can conclude that the scribe did not mean to include this line as an alternate or optional line, but that it was intended to be read as a part of the main text. This also raises several questions about the scribe’s transcription and editing process. When did the scribe catch his mistake? Is he copying from a manuscript which is consistent with his 25-line per folio rule? Or is he transcribing from a long, continuous manuscript and counting his lines?
Chris Ryan and Becky Musgrave encountered a similar problem in the Escorial Upsilon 1.1 in editing book 10 throughout this year, yet the scribe handled it in a different manner. Whereas the scribe of Venetus A decided to deal with this problem by marking lines α, β, γ, the scribe of Upsilon 1.1 put an asterisk at the end of the line that the missing line comes after, and then writes the line elsewhere on the folio with the word “stichoi” (“lines”) in front of it to let the reader know that it is part of the main text of the Iliad and not a scholion.
The first time we encountered this in Book 10 was on folio 126r, line 85: φθέγγεο· μὴδ᾽ ἀκεων ἐπ᾽ ἐ[page cuts off] ρχεο· τίπτε δέ σε χρεώ.
The line reads in the Venetus B: φθέγγεο· μὴδ᾽ ἀκεων ἐπ᾽ ἐμ᾽ ἔρχεο· τίπτε δέ σε χρεώ. We can tell that this line is not part of the scholia because the scribe actually puts a scholion marker within the line, and its corresponding scholion beneath it. The ink that the line is written in is also the same shade as the lines of the Iliad and darker than that of the main text of the scholia, so the scribe must have either purposely put the line out in the margin, or realized his mistake while he was writing the main text. The scribe typically puts 24 lines of Iliadic text on each folio, and each folio that contains a “stichoi” line only contains 23 lines in the main text (that is, 24 with the extra line counted).
The Venetus B has often been considered a “twin” manuscript of the Upsilon 1.1, since they almost always contain the same lines on each page and have very similar scholia, so whenever we encounter something unexepected in our editing of the Upsilon 1.1, we turn to the Venetus B for comparison. One reason that we are led to believe that these are cases of the scribe correcting his mistake and not an intentional editorial omission is by comparing the folio, to the corresponding folio 131r of the Venetus B. In the Venetus B, the line is written within the main text with no special treatment, which leads us to believe that the scribe of the Upsilon 1.1 placed this line in the margin simply because he made an error in the scribal process.
Editorial note: the undergraduate researchers at the Homer Multitext seminar happening right now at the Center for Hellenic Studies in Washington, DC will also be further investigating the question of “forgotten” lines, with a focus on Iliad 12 in the Venetus A. So stay tuned for more!
Thursday, June 19, 2014
Year In Review: The Latest Goings On of HMT
During the Fall 2013-Spring 2014 Academic year progress on the creation of digital editions of the Iliad manuscripts continued. Teams of undergraduates have been hard at work not only across the country but internationally. Several of our teams took a moment at the end of their academic years to report on what they have accomplished.
At College of the Holy Cross, teams were hard at work on Book 10 in the Venetus A, which was begun at the CHS Summer Seminar in 2013. When they weren't spending their Friday afternoons in the Isidore of Seville Lab, they were on the road giving presentations at Tufts and BU this spring, culminating in a final presentation at the Holy Cross Spring Academic Conference this April.
 |
| Holy Cross HMT at Tufts University Pictured left to right: Neel Smith, Rebecca Musgrave, Alexander Simrell, and Neil Curran |
At Brandeis University, work has continued on the Venetus B. The Fall was spent working steadily on Book 3. In the Spring, three new members joined their editing team and began to get familiar with the basics of the project, reading and editing the Venetus B hand. They are looking forward to acquiring a dedicated office space next year, where they can work with two other Classical Studies research projects at Brandeis.
At University of Washington in Seattle, their HMT team worked on Book 23 of the Venetus A, focusing their work primarily on the scholia, which included reading a number of them. Highlights include a fascinating (if convoluted) theory on how the third declension might derive from the first declension.
This summer promises to continue the productive streak. For the fifth summer in a row, undergraduates are hard at work at Holy Cross. This summer their work focuses on Book 11 in the Venetus A and Upsilon 1.1, allowing the teams to draw comparisons as they work on the manuscripts in parallel. The teams are also finishing Book 10 in the Venetus A and bringing previously edited books of the Venetus A up to the current editorial standards via automated testing.
Another two week seminar at the Center for Hellenic Studies is starting today, where students from five different colleges and universities will edit Book 12 of the Venetus A. More on the results of their work will be forthcoming.
Thursday, April 17, 2014
Oral Poetics and the Homer Multitext
One of the central research questions that drives the Homer Multitext is this: “How do you make a critical edition of an oral tradition, like that of the Homeric Iliad and Odyssey, that spanned a thousand years or more? What is the best way to represent the textual history of songs that were created in and for performance, but survive only in textual forms from later eras?” In our 2010 book, Iliad 10 and the Poetics of Ambush, Mary Ebbott and I attempted to demonstrate that a "multitextual" approach to Homeric poetry is useful not only for understanding the transmission of the text of the epics, but also for better understanding the poetics of oral poetry. We could not have written that book, which is meant to be a sustained demonstration of the workings of oral poetry over the course of an entire book of the Iliad, without the data and tools of the Homer Multitext that were available to us at that time.
As new ways of viewing and working with the surviving documents that transmit Homeric poetry become possible, Mary and I would like to continue to use them to enhance our understanding of the poetics of the Iliad and Odyssey. With that in mind, we have decided to revive a long neglected Oral Poetry blog, which we will maintain along with this one, and in close coordination with one another. The Oral Poetry blog will be devoted primarily to questions of poetics, while we will continue to make posts here about the manuscripts and papyri and what they tell about the system of oral poetry in which the Iliad and Odyssey were composed.
To kick off this phase of the Oral Poetry blog, we are planning a series of posts about the poetics of Iliad 2. You can read my initial post about this work here. You can also read a much older post on this blog about the transmission of the Catalogue of Ships from Book 2 here. It is the special treatment and seemingly controversial place of the Catalogue in the surviving manuscripts and papyri that drives us to try to better understand the poetics of this fascinating record of names and places.
As new ways of viewing and working with the surviving documents that transmit Homeric poetry become possible, Mary and I would like to continue to use them to enhance our understanding of the poetics of the Iliad and Odyssey. With that in mind, we have decided to revive a long neglected Oral Poetry blog, which we will maintain along with this one, and in close coordination with one another. The Oral Poetry blog will be devoted primarily to questions of poetics, while we will continue to make posts here about the manuscripts and papyri and what they tell about the system of oral poetry in which the Iliad and Odyssey were composed.
To kick off this phase of the Oral Poetry blog, we are planning a series of posts about the poetics of Iliad 2. You can read my initial post about this work here. You can also read a much older post on this blog about the transmission of the Catalogue of Ships from Book 2 here. It is the special treatment and seemingly controversial place of the Catalogue in the surviving manuscripts and papyri that drives us to try to better understand the poetics of this fascinating record of names and places.
Sunday, April 13, 2014
Testing the HMT project’s technical underpinnings
In February, we noted the release of new draft specifications for the CTS URN notation that we use to cite texts, and the CTS protocol that we use to retrieve texts in the Homer Multitext project. Since the publication of the draft specifications, we have released updates of a suite of test data and of software using the test data to assess the compliance of a given CTS service with the current version of the protocol.
Together with version 1.6 of this software, the ctsvalidator servlet, we are today releasing version 0.9.0 of our implementation of the CTS protocol, sparqlcts. The new version of sparqlcts passes 100% of the ctsvalidator tests.
To recapitulate what we have released in 2014 in our work on CTS:
- Formal specifications for the Canonical Text Services protocol, and CTS URNs. The specifications include Relax NG schemas for a CTS Text Inventory (the catalogue of a CTS library), and Relax NG schemas for validating the responses to CTS requests.
- A test data set, documented in a valid CTS Text Inventory, and available in three formats:
- valid and well-formed XML
- tabular data in simple delimited text files
- RDF triples in .ttl format
- A set of 68 tests applying CTS requests to the test data set. The tests are defined in an XML file listing the request and parameters to be submitted to a running CTS installation. For each test, a corresponding XML file gives the expected responses to the request.
- The CTS Validator, a web-app that runs the tests against any online CTS service hosting the corpus of test-data.
- An implementation of the Canonical Text Services, sparqlcts, a Java web-app drawing its data from a SPARQL endpoint. When the SPARQL end point is hosting the corpus of test data, sparqlcts passes 68 out of 68 of our defined tests.
This of course does not mean that sparqlcts is necessarily flawless (there may be problems that ctsvalidator does not test for), but it is an important milestone. One of the most profound implications of digital scholarship is that when we can automate the testing of digital work, we should invert the humanist’s traditional order of composition and assessment: specify the automated test first, then work until you pass the test. This applies to the software we use, too. When we next update our online services, we can be confident that our text service has successfully passed 100% of a challenging series of tests.
Links
- ctsvalidator (servlet, and tests): github repository
- sparqlcts: github repository
Christopher Blackwell and Neel Smith, project architects
Monday, March 31, 2014
Got git?
Over the past several years, github (https://github.com/) has emerged as the primary site for sharing openly licensed software. More recently, it has begun to assume a comparably important role in sharing openly licensed data; from the perspective of the Homer Multitext project, it’s tempting to say that you can have “as many githubs as you please.” (For a few examples of open datasets on github ranging from wedding invitations to arrangements of organ accompaniment for Gregorian chant, see this recent article. )
While the Homer Multitext project has relied on publicly available version control systems for years, and has specifically used the git version control system since 2012, we have only recently taken advantage of github’s option to group repositories by organization. To simplify the task of following the varied work in progress connected with the HMT, we have created two github organizations, homermultitext and cite-architecture.
- Repositories for the HMT data archive and digital services of the Homer Multitext project belong to the homermultitext organization. See http://homermultitext.github.io/.
- The CITE architecture is a generic architecture for working with citable scholarly data. It was originally developed specifically for the Homer Multitext project, and underpins all the digital work on HMT. See links to its repositories at http://cite-architecture.github.io/.
If you are new to version control in general or git in particular, you can probably find local expertise on your college or university campus; a little googling for help will certainly turn up an embarrassment of riches.
Christopher Blackwell and Neel Smith, project architects
Thursday, February 27, 2014
Publishing the HMT archive
The editorial work of the Homer Multitext project is ongoing, and, as good photography of more manuscripts and papyri becomes available, is open-ended. While we have provided openly licensed access to our source images and editorial work in progress since our first digital photography in 2007, we have not previously offered packaged publications of our archive.
That is changing in 2014. The project’s editors have decided on a publishing cycle of roughly three issues a year (since our work tends to be concentrated around an academic calendar of fall term, spring term, and summer work). Published issues of the project archive must satisfy four requirements.
- The issue must be clearly identified. Our releases are labelled with a year and issue number: our first issue is 2014.1.
- All content published in a given issue must pass a clearly identified review process. Teams of contributing editors work in individual workspaces. (We use github repositories to track the work history of these teams.) When a block of work passes a series of manual review and automated tests, it migrates from “draft” to “provisionally accepted” status and is added to the project’s central archival repository. This is the repository that we are publishing for the first time this week.
- All published material must be in appropriate open digital formats. Apart from our binary image data, all the data we create are structured in simple tabular text files or XML files with published schemas.
- All published material must be appropriately licensed for scholarly use. All of our work is published under a Creative Commons Attribution-ShareAlike license. (Licenses for some of our image collections additionally include a “non-commercial” clause: in those cases, a license for commercial reuse must be separately negotiated with the copyright holder.)
Access to the Published Digital Archive
The published packages are available for download from http://beta.hpcc.uh.edu/hmt/archival-publications as zip files. An accompanying README explains the contents of each zip file.
We are also distributing our published issues as nexus artifacts (previously mentioned briefly here), a system that allows software to identify and retrieve published versions automatically. Whether manually or automatically downloaded, it now becomes possible for scholars (and their software) to work with citable data sets from the constantly changing archive of the HMT project.
Tracking Work in Progress
We will continue to make our work in progress available. For easy access to the current state of “provisionally accepted” material in our archive, we also generate a nightly set of packages. These are available for manual download here, but are not distributed through our nexus server.
They should be considered unpublished: other publications should cite only published issues of the archive.
They should be considered unpublished: other publications should cite only published issues of the archive.
Like our individual editorial teams, we manage our publication repository through github: http://homermultitext.github.io/. Our data archive includes a publicly available issue tracker where you can submit questions or bug reports, and follow our progress.
More technical information
If you’re interested in technical information about how we develop the published archive and use it to build applications, Christopher Blackwell and I have recently published a discussion here.
Links
- Downloadable zip files of published data: http://beta.hpcc.uh.edu/hmt/archival-publications
- Nightly versions of “provisionally accepted” work: http://beta.hpcc.uh.edu/hmt/nightlies
- Homer Multitext project on github: http://homermultitext.github.io/
- Issue tracker for the publication archive: https://github.com/homermultitext/hmt-archive/issues
- maven coordinates for automated retrieval of packages in group org.homermultitext, with version number 2014.1:
- hmt-collections (CITE Collections)
- hmt-images (documentary information from the project’s Image Collections; binary image data for the cataloged images may be downloaded from http://amphoreus.hpcc.uh.edu/hmt/hmt-image-archive/)
- hmt-indices (CITE Indices)
- hmt-editions (editions of texts), in two formats identified with maven type
- xml (TEI-compliant XML)
- tabulated (tabular representation)
- hmt-rdf (Complete represenation of the published issue as an RDF graph in TTL format)
Saturday, February 8, 2014
Technically speaking ...
For over a decade, the Homer Multitext project has been exploring how to represent a multitext in digital form. For some of our essential work, we have been able to adopt well understood practices (such as how to use XML markup to structure a diplomatic edition of a text). In other aspects of our work, we are faced with issues that have not been explored in prior work on digital scholarship, and have had to define new standards.
We have devoted special attention to the fundamental question of how to cite texts in a form that is independent of any specific technology and sufficiently rigorously defined for computers to use. We have defined the syntax and semantics for a notation for citing texts that is based on the Internet Engineering Taskforce's Uniform Resource Name (URN) notation. We call this notation the Canonical Text Service URN, or CTS URN.
We have also defined a protocol for a networked service that understands the CTS URN notation, and can retrieve passages of texts. Unsurprisingly, we call this the Canonical Text Service protocol, or CTS protocol.
We have worked hard to ensure that the technical design of our notation and service fully satisfies the needs of the Homer Multitext project, but is not limited to or in any way specific to the HMT project's corpus of texts. Both of us have applied the CTS notation and CTS service protocol to a range of other projects, not limited to Greek or Latin texts. As our work on these two technical projects has matured, we have found more and more interest in it from scholars working with canonically citable texts.
This week, we were able to complete revisions for a new version of the specification for both the CTS URN notation and CTS protocol. It was especially gratifying that we were able to complete this work during a visit to Leiden University, where we were graciously hosted by Ineke Sluiter and her colleagues, a new group of collaborators on HMT who first participated in the summer 2013 seminar at the Center for Hellenic Studies.
The specifications:
- The CTS URN specification (version 2.0, release candidate 1): http://www.homermultitext.org/hmt-docs/specifications/ctsurn/
- The CTS protocol specification (version 5.0, release candidate 1): http://www.homermultitext.org/hmt-docs/specifications/cts/
Christopher Blackwell and Neel Smith, HMT project architects
Subscribe to:
Comments (Atom)